Computer System Architecture - Central Processing Unit
A pipelined processor uses a 4-stage instruction pipeline with the following stages : Instruction fetch (IF), Instruction decode (ID), Executive (EX) and Writeback (WB). The arithmetic operations as well as the load and store operations are carried out in the EX stage. The sequence of instructions corresponding to the statement X = (S – R* (P + Q))/T is given below. The values of variables P, Q, R, S and T are available in the registers R0, R1, R2, R3 and R4 respectively, before the execution of the instruction sequence.



- Option : C
- Explanation : Read After Write:
1. ADD ⇾ MUL (because of R5)
2. MUL ⇾ SUB (because of R6)
3. SUB ⇾ DIV (because of R5)
4. DIV ⇾ STORE (because of R6)
Write After Read
1. MUL ⇾ SUB (because of R5)
2. DIV ⇾ STORE (because of R6)
Write After Write
1. ADD ⇾ SUB (because of R5)
2. MUL – DIV (because of R6)
A pipelined processor uses a 4-stage instruction pipeline with the following stages : Instruction fetch (IF), Instruction decode (ID), Executive (EX) and Writeback (WB). The arithmetic operations as well as the load and store operations are carried out in the EX stage. The sequence of instructions corresponding to the statement X = (S – R* (P + Q))/T is given below. The values of variables P, Q, R, S and T are available in the registers R0, R1, R2, R3 and R4 respectively, before the execution of the instruction sequence.
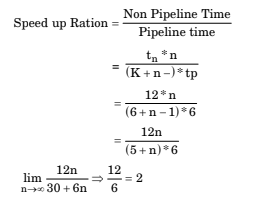

- Option : B
- Explanation : For each of the three instruction four stages will be
there. Since ,it is a pipelined processor, so one instruction may be fetched while other is being decoded
or executed or written back action performed in
each clock cycle may be represented as
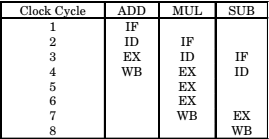
Only, two instructions cannot be executed simultaneously.
Consider the following program segment. Here R1, R2
and R3 are the general purpose registers.
Assume that the content of memory location 3000 is
10 and the content of the register R3 is 2000. The
content of each of the memory locations from 2000 to
2010 is 100. The program is loaded from the memory
location 1000. All the numbers are in decimal.
- Option : D
- Explanation : Ist memory reference R1 ⇽ M[3000] and then in
the loop which runs for 10 times, because the
content of memory location 3000 is 10 given in
question and loop will run 10 times as
{
R2 ⇽ M[R3]
M[R3] ⇽ R2
}
So Two memory reference every iteration
10 * 2 = 20
Total = 20 + 1 = 21
