Computer System Architecture - Pipeline and Vector Processing


- Option : D
- Explanation : For 6 stages, non-pipelining takes 6 cycles
There were 2 stall cycles for pipelining for 25% of
the instructions
So pipe line time = [1+(2 25/100)] = 3/2 = 1.5
Speed up = Non– pipeline time/Pipeline time = 6/1.5
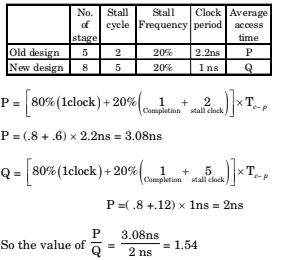
- Option : C
- Explanation : Peak clock frequency = 1 / Maximum latency
Maximum of latencies is minimum in P3
i.e. P1 : f = 1/2 = 0.5 GHz
P2 : f = 1/1.5 = 0.67 GHz
P4 : f = 1/1.1 GHz
P3 : f = 1/1 GHz = 1
Thus P3 is be the right answer
- Option : A
- Explanation : Speedup = Execution Time Old/Execution Time New Execution Time Old = CPI Old * Cycle TimeOld
[Here CPI is Cycles Per Instruction] = CPIOld * Cycle Time Old
= 4 * 1/2.5 Nanoseconds
= 1.6 ns
Since there are no stalls, CPUnew can be assumed 1 on average.
Execution Time New = CPInew
* Cycle Timenew
= 1 * 1/2
= 0.5
Speedup = 1.6/0.5 = 3.2