Computer System Architecture - Pipeline and Vector Processing
| S1 | S2 | S3 | S4 | |
| I1 | 2 | 1 | 1 | 1 |
| I2 | 1 | 3 | 2 | 2 |
| I3 | 2 | 1 | 1 | 3 |
| I4 | 1 | 2 | 2 | 2 |
for (i = 1 to 2) {I1; I2; I3; I4;}


- Option : D
- Explanation :
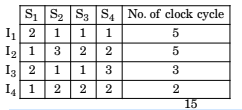
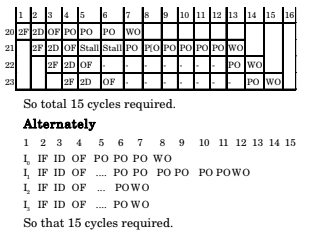
1st time for loop required is cycle and again second time 15 cycle
So, total = 30 cycle
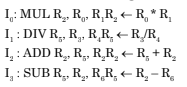
- Option : B
- Explanation : Pipeline registers overhead is not counted in
normal time execution
So the total count will be
5 + 6 + 11 + 8 = 30 [without pipeline]
Now, for pipeline, each stage will be of 11 n-sec (+ 1 n-sec for overhead).
and, in steady state output is produced after every pipeline cycle. Here, in this case 11 n-sec. After adding 1n-sec overhead, We will get 12 n-sec of constant output producing cycle.
dividing 30/12 we get 2.5
14. Register renaming is done in pipelined processors
- Option : A
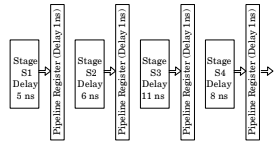
- Explanation : Given: Five stage instruction pipeline Delays for FI, DI, FO, EI and WO are 5, 7, 10, 8, 6 ns resp.
To find: Time needed to execute 12 instruction prog.
Analysis: Since the max. time taken by any stage is 10 ns and additional 1 ns is required for delay of buffer. Therefore total time for an instruction to pass from one stage to another is 11ns. Now instructions are executed as follows:Now when I4 is in its execution stage we detect the branch and when I4 is in WO stage we fetch I9 so time for execution of instructions from I1 to I4 is = 11*5 + (4 – 1)*11 = 88 ns.
And time for execution of instructions from I9 to I12 is = 11*5 + (4 – 1)*11 = 88 ns. = 88 ns. But we have 11ns when fetching I9 i.e. I9 requires only 44 ns additional instead of 55 ns because time for fetching I9 can be overlap with WO of I4.
Hence total time is = 88 + 88 – 11 = 165 ns
