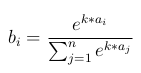info@avatto.com
+91-9920808017
36. Consider a vector a ∈ Rn and let b ∈ Rn be the output of the softmax function application to this vector and we have a parameter k such that If k = 1 then we get the default softmax function. Now, for simplicity, let us assume that all elements of a are positive. Further, let us assume that the j-th element of the maximum/largest element of a. It should be obvious that the corresponding element of b will also be the maximum/largest element of b. Now suppose we set k = 2, then what will happen to the j-th entry of b.
It will remain the same as the case when k = 1 because now k = 2 appears in the denominator also
It will be greater than the case when k = 1
It will be lesser than the case when k = 1
Can't say as it will depend on the other values in a
Your email address will not be published. Required fields are marked *
Report
Name
Email
Website
Save my name, email, and website in this browser for the next time I comment.
Comment
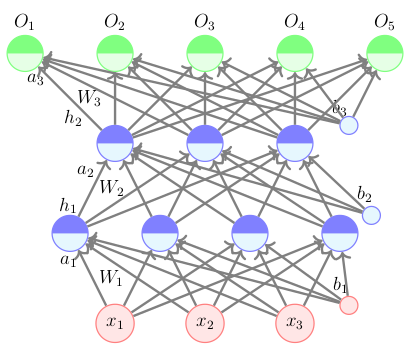
37. Consider the feedforward neural network in the figure shown below which has one inner layer, two hidden layers and one output layer. The input x to this network ∈ R3 and the number of neurons in the two hidden layers and the output layer is 4, 3, 5 respectively. Each layer is fully connected to the next layer, i.e., there is a weight connecting every neuron in layer i to every neuron in layer i+1. Also note that every neuron in the hidden and output layers has a bias connected to it. The activation function used in the hidden layers is the logistic function as defined in the lecture and the output function the softmax function. Now suppose that all the weights in layer 1 are 0.05 i.e., each the 3*4 = 12 elements of the matrix W1 has a value 0.05. Similarly, let us assume all the weights in layer 2 are 0.025, i.e., each of the 4*3 = 12 elements of the matrix has a value 0.025. Also, let us assume that all the weights in layer 3 are 1.0 i.e., each of the 3*5 = 15 elements of the matrix W3 has a value 1. Finally, the bias vectors for 3 layers are as follows: b1 = [0.1, 0.2, 0.3, 0.4] b2 = [5.2, 3.2, 4.3] b3 = [0.2, 0.45, 0.75, 0.55, 0.95] Now, suppose we feed the input x = [1.5, 2.5, 3] to this network, what will be the vector of O3 (i.e., the value output by the third neuron in the output layer).
0.132
0.189
0.229
0.753
38. In order to capture dynamic of a highly dynamic process, we should go for
Back-propagation neural network.
Radial basis function neural network.
Recurrent neural network.
Mamdani approach of fuzzy reasoning tool.
39. Which one of the following statements is not applicable to Self-Organizing Map (SOM)?
SOM is a dimensionality reduction technique.
SOM can be used as a clustering tool.
SOM uses the principle of supervised learning.
SOM uses the principle of un-supervised learning.
40. Which one of the following statements is FALSE?
In SOM, the aim of competition is to declare a winner.
In SOM, the synaptic weights are updated through the principle of cooperation.
SOM is a distance-preserving tool.
SOM is a topology-preserving tool.
Login with Facebook
Login with Google
Forgot your password?
Lost your password? Please enter your email address. You will receive mail with link to set new password.
Back to login